LAWD
Liga Acadêmica de Desenvolvimento Web abre seleção para estudantes de todos os cursos da universidade
Sem exigir experiência prévia, seleção oferece vagas técnicas e administrativas. Participação vale como extensão
Dando continuidade ao artigo anterior, neste artigo apresento uma resenha comentada do quinto capítulo “As quatro ondas da IA” do livro de Kai-Fu Lee “Inteligência Artificial: como os robôs estão mudando o mundo, a forma como amamos, nos relacionamos, trabalhamos e vivemos” de 2019. O meu objetivo é lançar luz sobre o que está acontecendo no oriente, mais especificamente na China, com relação à tecnologia de IA, pois esta já está embutida nos mais diversos produtos e serviços de software disponíveis e utilizados em todo o mundo. Também pretendo informar, como o fiz na primeira parte, as razões da China se desenvolver tanto e em tão pouco tempo em IA.
Inicialmente, trago, no quadro abaixo, o panorama apresentado pelo autor em tela, quanto às capacidades dos EUA e da China nas quatro ondas da IA (as quais explicarei a seguir) em 2018 e um prognóstico para cinco anos depois - 2023, no qual é possível perceber o franco desenvolvimento da China em relação ao EUA – a maior potência do ocidente em IA.
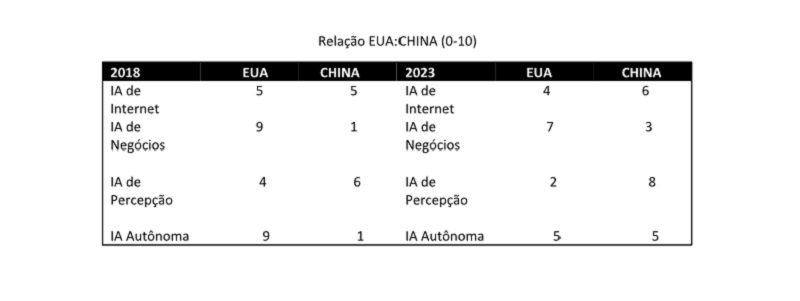
Como se vê, a China em 2018 estava bastante defasada em relação aos EUA na IA de Negócios e na IA Autônoma; estando na dianteira na IA de Percepção e empatada com os EUA na IA de Internet. Procurarei explicar, no decorrer deste texto, as razões para essa realidade.
Para 2023, Lee estima o avanço da China em todas as IA, ultrapassando os EUA em IA de Internet; aumentando a distância em relação à IA de Percepção e empatando com os EUA na IA Autônoma. Da mesma maneira, pretendo apresentar as explicações do autor para estas previsões.
Segundo Kai-Fu Lee (2019, p.131)
“As duas primeiras ondas – IA da internet e dos negócios – já estão ao nosso redor, remodelando nossos mundos digital e financeiro de maneira que mal conseguimos registrar.
A IA de percepção está agora digitalizando nosso mundo físico, aprendendo a reconhecer nossos rostos, entender nossos pedidos e “ver” o mundo ao nosso redor.
A IA autônoma virá por último, mas terá um impacto mais profundo em nossa vida.
Todas essas quatro ondas se alimentam de diferentes tipos de dados, e cada uma delas apresenta uma oportunidade única para que os estados Unidos ou a China assumam a liderança.”
A seguir, comentarei sobre as características de cada onda da IA: da primeira – IA de Internet, à quarta – IA Autônoma, lembrando ao leitor que todas as ondas envolvem o aprendizado profundo de máquina, o qual, conforme expliquei no artigo anterior publicado neste canal em 11/03/20, tem como requisitos o poder de computação e a grande quantidade de dados (big data). E, para transformar a IA em produtos e serviços de softwares rentáveis, são ainda necessários bons engenheiros de algoritmos, empreendedores algozes e um ambiente político favorável a investimentos na área.
IA DA INTERNET
A Ia da internet utiliza algoritmos conhecidos como “motores de recomendação: sistemas que aprendem nossas preferências pessoais e, em seguida, veiculam conteúdos escolhidos a dedo para nós”. (Id. Ibid., p.132) O algoritmo utiliza os dados que foram “rotulados” na interação do usuário com o serviço (site) que ele está acessando: comprado versus não comprado, clicado versus não clicado e assim por diante. Essas etiquetas são utilizadas para recomendar mais conteúdo que provavelmente lhe interessa. Como se diz no popular: não existe almoço de graça. Em interações com a IA da internet, o usuário é o produto!
Concordo com Lee quando ele afirma que possivelmente o usuário da internet é “beneficiário (ou vítima, dependendo de como valorize seu tempo, sua privacidade e seu dinheiro) da IA da internet”. (Id. Ibid.) Para conhecer melhor sobre o porquê desta afirmação, sugiro a leitura do livro “21 lições para o século 21” de Yoval Noa Harari de 2019, objeto de estudo do GEPIED/UFS/CNPq no ano passado e que foi a referência principal das sete comunicações apresentadas pelo GEPIED durante o II Encontro Norte-Nordeste da Associação Brasileira de Pesquisadores em Cibercultura (ABCiber) ocorrido na Universidade Tiradentes em novembro de 2019.
Um dos usos populares da IA da internet são os algoritmos editores de notícias, como o algoritmo da empresa chinesa Toutiao.
De acordo com o autor (p. 133-134)
“Os motores de IA da Toutiao vasculham a internet em busca de conteúdo, usando processamento de linguagem natural e visão computacional para compilar artigos e vídeos de uma vasta rede de sites de parceiros e colaboradores comissionados. Em seguida, usa o comportamento anterior de seus usuários – seus cliques, leituras, visualizações, comentários e assim por diante – para organizar um feed de notícias altamente personalizado, adaptado aos interesses de cada pessoa. [...] É um ciclo de feedback positivo que criou uma das plataformas mais viciantes na internet, com usuários passando uma média de 74 minutos por dia no aplicativo.” (grifo nosso)
A fim de garantir a veracidade das informações, o algoritmo da Toutiao também utiliza o aprendizado de máquina para policiar o conteúdo veiculado. Ele é treinado com o relato dos usuários sobre fake news veiculadas, a fim de detectá-las na rede. A Toutiao até desenvolveu um algoritmo gerador de fake news e depois colocou dois desses algoritmos, como programas de computador, para se enfrentarem, competindo para se enganarem com o objetivo de serem aprimorados. Então o algoritmo curador de notícias tem dados suficientes para ser treinado e reconhecer fake news quando elas são postadas.
Como mostrado no quadro, em 2018 a China e os EUA estavam empatados nessa categoria de IA. Mas como a China tem mais usuários de internet do que os EUA e a Europa juntos etiquetando dados, Lee prevê a superioridade chinesa para daqui a cinco anos nessa aplicação da IA.
IA DE NEGÓCIOS
Nesta fase, os algoritmos de IA se beneficiam da estruturação dos dados armazenados pelas empresas, decorrentes da zeitgeist[1] empresarial. Assim, de acordo com o autor, “a primeira onda da IA aproveita o fato de que os usuários de internet estão etiquetando dados automaticamente enquanto navegam. A IA de negócios tira proveito do fato de que as empresas tradicionais também etiquetaram automaticamente quantidade de dados por décadas.” (Lee, p. 136)
Como expliquei no artigo anterior, um dos requisitos para que os algoritmos aprendam bem é a disponibilidade de grandes volumes de dados, ou seja, big data. Nesse “oceano” de dados, os algoritmos de mineração de dados (data mining)[2] fazem correlações ocultas que são imperceptíveis ao cérebro humano. Isso porque, segundo Lee, “os humanos, em geral, fazem predições com base em preditores fortes, um punhado de pontos de dados altamente correlacionados a um resultado específico, quase sempre em uma relação de causa e efeito.” (Id. Ibid).
É no setor financeiro, devido às características do negócio, que se encontram os bancos de dados mais estruturados. Por isso, segundo Lee, os EUA “construíram uma forte vantagem nas primeiras aplicações de negócios. Grandes empresas norte-americanas já coletam gigantescas quantidades de dados e os armazenam em formatos bem estruturados” (Id. Ibid, p. 137-138). Já a China, que pulou a fase dos “cartões de crédito” e foi direto para a fase dos pagamentos móveis através de Apps como o WeChat e o Alipay, não possui dados suficientes sobre o históricos de pagamentos dos seus usuários, pois só processam dados sobre o saldo bancário dos usuários, não levando em consideração a capacidade de tomar empréstimos de cada um deles.
Foi nesse vácuo que surgiu o aplicativo chinês Smart Finance, cujos algoritmos de aprendizado profundo não analisam somente as métricas óbvias (por ex. qual é o saldo da WeChat Wallet do usuário), mas fazem previsão a partir de dados que parecem irrelevantes para um analista financeiro humano, como por exemplo, a velocidade com que o usuário digitou a sua data de nascimento e quanta bateria resta no seu celular. Como questiona Lee:
“O que a bateria do celular de um candidato tem a ver com o crédito? Esse é o tipo de pergunta que não pode ser respondida em termos de causa e efeito simples. [...] Treinando seus algoritmos em milhões de empréstimos – muitos que foram pagos e alguns que não – a Smart Finance descobriu milhares de características fracas que estão correlacionadas com a credibilidade, mesmo que essas correlações não possam ser explicadas de uma maneira simples que os humanos possam entender.” (Id. Ibid, p. 139)
Outra aplicação da IA de negócios é em aplicativos de diagnósticos médicos para uma variedade de doenças, democratizando o acesso à saúde. A empresa chinesa RXThinking está treinando algoritmos médicos para diagnosticar doenças e depois serem distribuídos por toda China. Como diz Lee (p. 141):
“Com dados suficientes de treinamento – nesse caso, registros médicos precisos – uma ferramenta de diagnóstico com tecnologia IA poderia transformar qualquer profissional médico em um superdiagnosticador, um médico com experiência em dezenas de milhões de casos, uma capacidade incomum de detectar correlações ocultas e uma memória perfeita que pode ser usada.”
Porém,
“O aplicativo nunca substitui um médico – que sempre pode escolher ignorar as recomendações do aplicativo – mas percorre mais de 400 milhões de registros médicos existentes e examina continuamente as publicações médicas mais recentes para fazer recomendações. Ele dissemina o conhecimento médico de primeira linha igualmente por sociedades altamente desiguais.” (Id. Ibid, p. 141)
Outra área que pode ser muito assistida pela IA de negócios é a justiça. Tal qual acontece com as ferramentas de IA para ajudar os médicos a diagnosticarem doença, a ferramenta chinesa iFlyTek assumiu a liderança na área jurídica, ajudando os juízes com recomendações orientadas por dados. Lee comenta que
“Os estudiosos de direito norte-americanos têm demonstrado grandes disparidades na condenação dos Estados Unidos com base na raça da vítima e do réu. E os vieses judiciais podem ser muito menos maliciosos do que o racismo: um estudo com juízes israelenses mostrou que eles são muito mais severos em suas decisões antes do almoço e mais brandos na concessão de liberdade condicional depois de uma boa refeição.”
Os exemplos citados demonstram a dificuldade humana em lidar com a complexidade envolvida nos fenômenos. Vale aqui fazer um gancho com o conceito “Pensamento Sistêmico”, o qual Peter Senge utiliza como uma das cinco disciplinas que se deve desenvolver em uma Organização de Aprendizagem a fim de que a organização possa aprender com os seus colaboradores (teoria que utilizei na minha tese aplicada à escola); ou com o conceito “Visão Sistêmica” de Capra; ou com o conceito “Pensamento Complexo” de Edgar Morin, mediante os quais podemos afirmar que não é mais possível compreender a complexidade dos fenômenos atuais a partir da simplificação e consequente fragmentação dos mesmos pela lente do Método Cartesiano. Nesse sentido é que almejamos uma Educação que contemple forjar modelos mentais flexíveis e aptos a atuar com a complexidade. O computador quando processa os algoritmos “inteligentes” nos apresentam padrões indecifráveis por mentes cartesianas, mas que podem ser melhores compreendidos por mentes que pensam complexo.
IA DE PERCEPÇÃO
Nessa terceira onda, os algoritmos vão além de simplesmente fazer casamento de padrão com os dados. Eles agora conferem significado aos dados, analisando a semântica de sentenças completas. Como diz kai-Fu Lee,
“A terceira onda de IA trata de ampliar e expandir esse poder para todo nosso ambiente de vida, digitalizando o mundo ao nosso redor através da proliferação de sensores e dispositivos inteligentes. Esses dispositivos estão transformando nosso mundo físico em dados digitais que podem ser analisados e otimizados por algoritmos do aprendizado profundo.” (Id. Ibid, p. 144)
Por exemplo, o Amazon Echo digitaliza o áudio nas residências a fim de atender as ordens das pessoas para controlar os utensílios domésticos e as luzes da casa; o Brain do Alibabá usa câmeras para digitalizar o fluxo de tráfego urbano para que os algoritmos de aprendizado profundo reconheçam objetos, enquanto as câmeras do iPhone X da Apple e do Face ++ utilizam os dados para reconhecer a face do dono do celular e da carteira de dinheiro digital para protegê-los do uso indevido por outra pessoa.
Lee designou esses ambientes misturados (dados digitais e dados físicos) de OMO: on-line-merge-off-line. O OMO integra os dois mundos (on-line e físico), trazendo “a conveniência do mundo on-line para o off-line e a rica realidade sensorial do mundo off-line para o on-line.” (Id. Ibid, p. 145). Um exemplo de aplicação OMO é o aplicativo de um restaurante na China. Ele se conecta ao aplicativo Alipay para permitir que o cliente pague a conta em um terminal digital depois de uma rápida confirmação facial. Não é preciso dinheiro, cartão de crédito/débito ou celular. Outro exemplo vem de um supermercado na China: o carrinho de compras recebe o cliente como se fosse um “velho amigo” que conhece os hábitos de consumo dele, exibe a sua lista usual de compras na tela acoplada ao carrinho e ainda oferece boas sugestões de ofertas, sempre baseando-se nas particularidades de consumo de cada cliente.
Lee também vislumbra a educação escolar sendo “alimentada” por OMO. Segundo ele, todos os sistemas atuais utilizados para dar suporte ao processo de ensino-aprendizagem foram desenhados segundo o modelo fabril, através do qual todos os alunos são forçados a aprender no mesmo ritmo, da mesma maneira, no mesmo lugar e ao mesmo tempo, pois as escolas, infelizmente, ainda adotam uma abordagem de “linha de montagem”. Discuti essa problemática na minha tese “Um ambiente ergonômico de ensino aprendizagem-informatizado” (UFSC, 2002) e, já àquela época, afirmei que a aprendizagem deveria ser conduzida sob a égide da ergonomia (cognição ergonômica). Embora não propus uma tecnologia para esse fim, vislumbrei a possibilidade do uso da IA, quando discorri sobre os agentes inteligentes. Quem se interessar em ler a tese, segue o link dela na Biblioteca Digital de Teses e Dissertações (BDTD) do Instituto Brasileiro de Informação em Ciência e Tecnologia (IBICT): https://repositorio.ufsc.br/xmlui/handle/123456789/83000.
Portanto, Lee apresenta cenários onde a IA de Percepção poderá atuar na educação. Segundo ele, “as habilidades de percepção, reconhecimento, e recomendação da IA podem adaptar o processo de aprendizado a cada aluno e liberar os professores para mais tempo de instrução individual.” E, depois que o aluno for para casa, o sistema informático “combinará o perfil do estudante com algoritmos geradores de perguntas para criar tarefas de casa adaptadas com precisão às habilidades de cada um deles” (Id. Ibid, p. 150), de acordo com conceito de “cognição ergonômica” que desenvolvi na minha tese.
Lee afirma que a China se desenvolve com muita rapidez em IA de Percepção na educação devido ao seu zeitgeist cultural, pois a maioria dos pais chineses têm filho único e, assim, “investem dinheiro em sua educação, resultado de valores profundamente enraizados entre os chineses, intensa competição por vagas nas universidades e um sistema público de educação de qualidade”. Adotando a cognição ergonômica (Schneider, 2002) como princípio, muitas dessas ferramentas já existem na China e “constituem um novo paradigma de educação com tecnologia IA, que une os mundos on-line e off-line para criar uma experiência de aprendizagem adaptada às necessidades e habilidades de cada aluno”. (Id. Ibid, p. 151). Resta-me observar que aquilo que apresentei em 2002 como o porvir desejado para a educação brasileira, já é realidade na China, enquanto, por aqui, continuamos a investir numa educação inapropriada para a contemporaneidade, inserindo tecnologia para reforçar o método cartesiano no modelo de ensino-aprendizagem.
Como disse, todos os algoritmos de aprendizado profundo exigem oceanos de dados para possibilitar a aprendizagem dos padrões representados nos dados. Isso significa que será necessário permitir que os nossos dados sejam capturados se quisermos usufruir dos recursos OMO. Lee assevera - e eu concordo - que “não há resposta certa para questões sobre que nível de vigilância social é um preço que vale a pena pagar para maior conveniência”. A coleta de dados que resulta no fenômeno Big Brother que agora se concretiza, foi maravilhosamente antecipado no romance “1984” do escritor britânico George Orwell, publicado em 1949 e no livro “Admirável mundo novo” do romancista Aldous Huxley em 1932. Assim, cabe a cada país decidir sobre a medida de equilíbrio entre a privacidade e os dados públicos. A Europa adotou uma abordagem mais rigorosa quanto à proteção dos dados privados. Os EUA ainda não se decidiram sobre qual é a medida melhor para eles. Enquanto a China, em 2017, implementou a sua Lei de Segurança Cibernética, com a qual pretende administrar punições para a coleta e venda ilegal (ou seja, sem a permissão) de dados dos usuários. Mas o povo chinês aceita de forma mais natural que os seus dados sejam capturados, trocando privacidade por conveniência oferecida pela IA de Percepção. Nós, ocidentais, somos mais cautelosos, embora a maioria dos usuários de apps cedam seus dados pessoais sem saber que os estão oferecendo para alimentar os algoritmos de IA, em troca de alguma conveniência no mundo digital.
IA AUTÔNOMA
Nesta quarta fase da Inteligência Artificial, a automação usando IA inicialmente será empregada em ambientes mais estruturados, como fábricas, armazéns e fazendas. Depois a automação migrará paulatinamente para os ambientes não estruturados, como as ruas, shoppings centers, restaurantes e etc. Assevera Lee: “Quando as máquinas puderem ver e ouvir o mundo ao redor, estarão prontas para se mover por ele com segurança e trabalhar de forma produtiva.” (Id. Ibid, p. 156) Embora os robôs atualmente já serem automatizados, eles ainda não são autônomos, porque, apesar de repetirem uma ação, eles não podem tomar decisão, ou seja,
“podem executar tarefas repetitivas, mas não podem lidar com desvios ou irregularidades nos objetos que manipulam. No entanto, fornecendo às máquinas o poder da visão, o sentido do tato e a capacidade de otimizar os dados, podemos expandir muito o número de tarefas que elas podem resolver.” (Id. Ibid, p. 157)
Atualmente na cidade chinesa Shenzhen, existe a maior fabricante de drones[3] no mundo: a fábrica DJI. A inteligência de enxame, ou seja, uma inteligência que permitirá às máquinas trabalharem de forma colaborativa impulsionará muito mais a China no tocante à Inteligência Autônoma, pois Shenzhen corresponde ao vale do silício da Califórnia/EUA, onde são fabricadas várias espécies de hardware. Então, conforme a previsão de Lee, embora “as tecnologias de enxame ainda estão engatinhando, mas quando conectadas ao incomparável ecossistema de hardware de Shenzhen, os resultados serão impressionantes.” (Id. Ibid, p. 159) É o que conhecemos por Internet das Coisas – IoT (Internet of Things).[4]
No nicho dos carros autônomos, o Google[5] e a Tesla[6] adotaram estratégias diferentes de desenvolvimento, embora ambas abordagens sejam alimentadas pelo volume de dados gerados pelo uso dos seus carros.
Segundo o autor, “carros autônomos devem ser treinados em milhões, talvez bilhões, de quilômetros de dados para que possam aprender a identificar objetos e prever os movimentos de carros e pedestres” (Id. Ibid, p. 160). Isso significa que, quando qualquer carro autônomo encontra uma nova situação, todos os carros aprendem aquela nova situação.
A Google optou por uma abordagem lenta e constante, porém mais segura, para obtenção dos dados, por meio de uma frota pequena de carros. Já a Tesla adotou uma estratégia mais arrojada, instalando nos seus carros comuns equipamentos mais baratos de automação, o que possibilitou a produção de um maior volume de dados, quando do uso desses equipamentos pelos condutores dos carros. As duas abordagens geraram uma grande vantagem para a Tesla: Lee afirma que em “2016, o Google levava seis anos acumulando quase 2,5 milhões de quilômetros de dados de condução do mundo real. Em apenas seis meses, a Tesla tinha acumulado 75 milhões de quilômetros.” (Id. Ibid, p. 160) As duas abordagens apresentam prós e contras. O Google busca por uma segurança impecável nos seus automóveis, só disponibilizando os recursos de automação via IA depois de fartamente treinados; enquanto a Tesla, com a sua visão técnico-utilitarista, numa abordagem de implementação incremental, está desenvolvendo os recursos de automação em tempo real.
A China apostou no desenvolvimento incremental da IA autônoma nos automóveis, apoiando-se no volume de dados gerados pelos seus motoristas. Para isso, prevê a construção de estradas e outras novas infraestruturas especialmente fabricadas para acomodar os veículos autônomos. Já os EUA preferiram adotar uma estratégia de desenvolvimento para os seus carros autônomos que lhes permitam adaptar-se às estradas existentes. Assim, a China já está projetando a sua primeira autoestrada inteligente para veículos autônomos e elétricos e cidades inteiramente novas, como a Nova Área de Xiongan, a aproximadamente cem quilômetros ao sul de Pequim, uma cidade-modelo para o progresso tecnológico e sustentabilidade ambiental. Esta cidade está projetada para receber uma população de 2,5 milhões de pessoas, o equivalente à cidade de Chicago. Assim diz o autor, em tom de ironia: “a ideia de construir uma nova Chicago do zero é bastante impensável nos estados Unidos, mas na China é apenas uma peça do kit de planejamento urbano do governo.” (Id. Ibid, p. 162)
Portanto, pode-se prever um desenvolvimento célere da IA autônoma na China devido ao quadro que acabo de descrever: grandes quantidades de dados, desenvolvimento incremental dos algoritmos embarcados, construção de cidades com infraestrutura adequada à automação e IoT. Em 2018, o placar estava 9 a 1 para os EUA; para 2030, Lee prevê o empate de 5 a 5. Porém, é importante fazer uma ressalva: os problemas tecnológicos demandados pela IA autônoma exigem conhecimentos de ponta, ou seja, engenheiros de primeira linha (como os da Google e os da Tesla) e não apenas um time de bons engenheiros que sabem replicar o conhecimento. Dessa forma, os EUA tendem a manter a liderança. Mas, se as soluções de caráter técnico forem logo assimiladas pela indústria, o tipo da política de desenvolvimento – teste exaustivo de protótipos versus teste usando a experiência do usuário - dará vantagem para a China.
Finalmente, pouco importa quem liderará a indústria da Inteligência Artificial, pois sabemos que a tecnologia estará disponível no mercado global, independentemente qual o país que fabricou o produto. O que realmente importa é como as pessoas serão impactadas pelas tecnologias de IA. Se elas nos servirão enquanto tecnologias desenvolvidas pelo homem para serem facilitadoras das nossas vidas ou se elas se apresentarão como vetores de subjugação dos seus usuários.
Henrique Nou Schneider é professor no Departamento de Computação e no Programa de Pós-Graduação da UFS. Líder do Grupo de Estudos e Pesquisa em Informática na Educação/UFS-CNPq (GEPIED)
---
[1] Pronúncia: [Dzáit-Gáist]) é um termo alemão cuja tradução significa espírito da época ou sinal dos tempos, mas, em uma tradução mais apurada: espírito do tempo. O Zeitgeist significa, em suma, o conjunto do clima intelectual, sociológico e cultural de uma pequena região até a abrangência do mundo todo em numa certa época da história, ou as características genéricas de um determinado período de tempo. (WIKIPEDIA). Acesso em 19.04.20
[2] Prospecção de dados ou mineração de dados (também conhecida pelo termo inglês data mining) é o processo de explorar grandes quantidades de dados à procura de padrões consistentes, como regras de associação ou sequências temporais, para detectar relacionamentos sistemáticos entre variáveis, detectando assim novos subconjuntos de dados.
No campo da administração, a mineração de dados é o uso da tecnologia da informação para descobrir regras, identificar fatores e tendências-chave, descobrir padrões e relacionamentos ocultos em grandes bancos de dados para auxiliar a tomada de decisões sobre estratégia e vantagens competitivas.[1][2][3]
Esse é um tópico recente em ciência da computação, mas utiliza várias técnicas da estatística, recuperação de informação, inteligência artificial e reconhecimento de padrões. (WIKIPEDIA). Acesso em 19.04.20
[3] Veículo aéreo não tripulado (VANT), também conhecido como aeronave remotamente pilotada (ARP) ou ainda drone (do Inglês, zangão), é todo e qualquer tipo de aeronave que pode ser controlada nos 3 eixos e que não necessite de pilotos embarcados para ser guiada. Estes tipos de aeronaves são controladaos à distância por meios eletrônicos e computacionais, sob a supervisão de humanos, ou mesmo sem a sua intervenção, por meio de Controladores Lógicos Programáveis (CLP). (WIKIPEDIA). Acesso em 16/05/20.
[4] Em outras palavras, a internet das coisas nada mais é que uma rede de objetos físicos (veículos, prédios e outros dotados de tecnologia embarcada, sensores e conexão com a rede) capaz de reunir e de transmitir dados. É uma extensão da internet atual que possibilita que objetos do dia-a-dia, quaisquer que sejam, mas que tenham capacidade computacional e de comunicação, se conectem à Internet. A conexão com a rede mundial de computadores possibilita, em primeiro lugar, controlar remotamente os objetos e, em segundo lugar, que os próprios objetos sejam usados como provedores de serviços. (WIKIPEDIA). Acesso em 16/05/20.
[5] É uma empresa multinacional de serviços online e software dos Estados Unidos. O Google hospeda e desenvolve uma série de serviços e produtos baseados na internet e gera lucro principalmente através da publicidade pelo AdWords. A Google é a principal subsidiária da Alphabet Inc. (WIKIPEDIA). Acesso em 16/05/20.
[6] Tesla, Inc. (antigamente Tesla Motors, Inc.), é uma empresa automotiva e de armazenamento de energia norte americana, que desenvolve, produz e vende automóveis elétricos de alto desempenho, componentes para motores e transmissões para veículos elétricos e produtos à base de baterias. Foi fundada em 2003 pelos engenheiros Martin Eberhard e Marc Tarpenning em San Carlos, Califórnia. O seu nome é uma homenagem ao inventor e engenheiro eletricista Nikola Tesla. (WIKIPEDIA). Acesso em 16/05/20.